Filtres et lignes masquées : ce qu’Excel calcule réellement
C’est un autre piège très fréquent : on filtre un tableau, on ne voit plus qu’une partie des données… et on suppose instinctivement qu’Excel ne travaille plus que sur ce qui est affiché à l’écran. Dans la réalité, ce n’est presque jamais le cas.
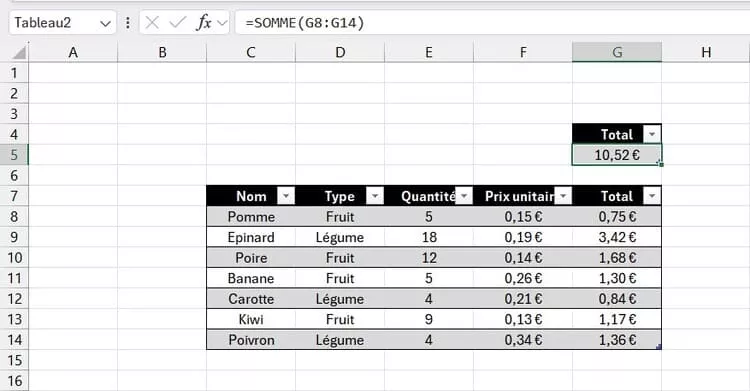
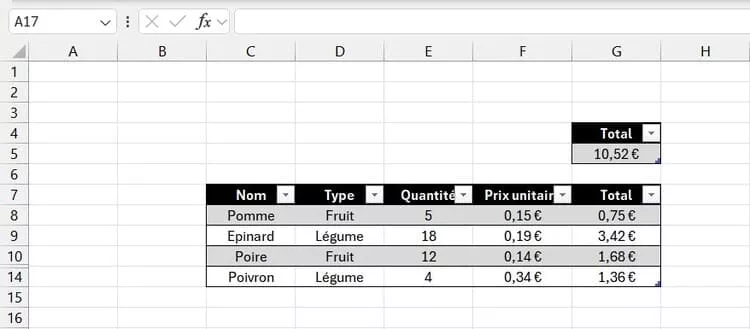
Par défaut, Excel continue de calculer sur l’ensemble de la plage, y compris sur les lignes masquées par un filtre ou cachées manuellement. Visuellement, vous avez l’impression de travailler sur un sous-ensemble de données, mais les formules, elles, prennent toujours tout en compte.
C’est ainsi que l’on obtient des totaux qui paraissent illogiques, des indicateurs qui ne correspondent pas aux lignes visibles, ou des écarts difficiles à expliquer.
Ce problème apparaît souvent lorsqu’on filtre un tableau pour analyser une période, un client ou une catégorie précise, puis qu’on regarde un total global en pensant qu’il reflète uniquement ce qui est affiché. Le chiffre semble plausible, donc on lui fait confiance… alors qu’il inclut en réalité des données invisibles.
Même chose avec les lignes masquées manuellement. Beaucoup pensent qu’une ligne cachée est exclue des calculs. Ce n’est pas vrai. Pour Excel, une ligne masquée reste une ligne comme les autres.
Ces situations sont particulièrement dangereuses parce qu’elles ne génèrent aucune alerte. Aucun message d’erreur, aucune cellule en rouge. Simplement un résultat qui paraît cohérent, mais qui ne correspond pas à ce que l’on croit analyser.
Encore une fois, Excel ne se trompe pas. Il applique sa logique. C’est l’utilisateur qui, sans s’en rendre compte, change le contexte visuel sans changer le contexte de calcul. Et plus on manipule les filtres dans un fichier mal structuré, plus ce décalage entre ce que l’on voit et ce qui est réellement calculé devient important.
Références cassées : quand vos formules pointent ailleurs sans que vous le sachiez
C’est probablement l’un des problèmes les plus sournois dans Excel. Au départ, tout fonctionne. Les formules sont correctes, les résultats semblent cohérents. Puis, au fil du temps, on insère une colonne, on supprime une ligne, on déplace un bloc de données, on copie une feuille et sans s’en rendre compte, certaines références changent.
Excel essaie bien de suivre les déplacements, mais il ne peut pas toujours préserver la logique métier du fichier. Il ajuste les adresses de cellules, pas l’intention derrière le calcul. Résultat : une formule peut continuer à fonctionner techniquement tout en pointant vers une mauvaise zone.
C’est exactement ce qui rend ces erreurs dangereuses. Il n’y a pas forcément de message d’alerte. La formule renvoie un nombre, parfois très proche de l’ancien résultat, et personne ne remarque que le périmètre de calcul a changé.
Ce phénomène apparaît souvent après l’insertion ou la suppression de lignes ou de colonnes, le déplacement de blocs de données, la duplication de feuilles ou des copier/coller successifs. Petit à petit, le fichier se transforme, mais les formules restent figées dans une logique qui n’est plus adaptée.
On croit travailler avec les bonnes données, alors que certaines formules pointent déjà ailleurs. Dans un fichier professionnel, c’est critique : un indicateur peut être faussé pendant des semaines sans que personne ne s’en rende compte, simplement parce qu’une référence a glissé.
Encore une fois, Excel n’a pas fait d’erreur. Il a appliqué ses règles. Ce sont les modifications successives du fichier, sans structure claire, qui finissent par casser la cohérence des calculs.
Copier / coller : l’ennemi silencieux de vos fichiers
Le copier / coller est l’un des gestes les plus utilisés dans Excel et aussi l’un des plus destructeurs quand il est mal maîtrisé.
On copie une cellule, on la colle ailleurs, tout semble fonctionner. Pourtant, à chaque collage, Excel transporte bien plus que de simples valeurs. Il peut aussi coller des formules, des formats, des références, voire des liaisons invisibles avec d’autres zones du fichier.
Petit à petit, sans s’en rendre compte, on introduit dans le classeur des formules copiées hors contexte, des formats incohérents, des références décalées et des cellules transformées en valeurs fixes.
Visuellement, tout paraît normal. Mais la logique interne du fichier commence à se fragmenter.
Un cas très fréquent consiste à remplacer une formule par sa valeur, simplement parce qu’on a collé sans y prêter attention. Le résultat reste affiché, donc on pense que tout va bien. Mais à la prochaine mise à jour des données, le calcul ne se fait plus. Et comme il n’y a pas d’erreur visible, le problème passe souvent inaperçu.
Autre situation classique : on copie une colonne entière pour gagner du temps, sans réaliser que certaines références ne sont plus adaptées à la nouvelle position. Les chiffres restent plausibles, mais ils ne correspondent plus exactement à ce qu’ils devraient représenter.
Avec le temps, ces petits copier/coller successifs transforment un fichier initialement propre en un assemblage de morceaux hétérogènes. Chaque nouvelle manipulation augmente le risque d’erreur, jusqu’au jour où plus personne ne comprend vraiment comment les calculs sont construits.
C’est pour cela que beaucoup de fichiers Excel deviennent instables : ils ne sont plus basés sur une logique claire, mais sur une accumulation d’actions rapides.
Pourquoi ce ne sont pas des bugs Excel ?
Quand les résultats deviennent incohérents, beaucoup pensent immédiatement qu’Excel est le problème. En réalité, dans l’immense majorité des cas, Excel fonctionne parfaitement. Il applique simplement les règles qu’on lui a données.
Si une cellule est vide, Excel la traite comme vide. Si une ligne est masquée, Excel continue de la calculer. Si une formule a été remplacée par une valeur, Excel n’a plus rien à recalculer. Si une référence a glissé, Excel suit la nouvelle adresse.
Le logiciel ne comprend pas l’objectif de votre fichier. Il ne sait pas ce que représente votre chiffre, ni ce que vous cherchez à analyser. Il se contente d’exécuter des instructions techniques.
Le problème vient donc rarement d’Excel lui-même. Il vient de la façon dont les fichiers sont construits, modifiés et enrichis au fil du temps, souvent sans structure claire ni méthode globale. On empile des corrections rapides, on ajoute des colonnes à la volée, on copie des blocs entiers pour gagner du temps… et on finit avec un fichier qui fonctionne encore, mais dont personne ne maîtrise vraiment la logique.
À ce stade, Excel ne fait plus que refléter les faiblesses du classeur. Ce n’est pas un bug. C’est une conséquence.
Comprendre cela est essentiel, car tant qu’on cherche un problème technique, on passe à côté du vrai sujet : la manière de concevoir un fichier Excel fiable.
Ce que ces erreurs révèlent sur votre façon d’utiliser Excel
Toutes ces situations ont un point commun : elles ne viennent pas d’un manque de fonctions, mais d’un manque de méthode.
Quand les calculs deviennent faux sans qu’on s’en rende compte, c’est presque toujours le signe que le fichier a été construit « au fil de l’eau ». On saisit des données ici, on ajoute une colonne là, on copie une formule pour aller plus vite, on masque des lignes pour y voir plus clair… sans jamais poser une vraie structure.
Résultat : Excel devient un empilement d’actions rapides plutôt qu’un outil organisé. On ne distingue plus clairement les zones de saisie, les zones de calcul et les zones de restitution. Les formules sont dispersées, les données sont mélangées, et personne ne sait vraiment où commence la logique ni où elle s’arrête.
À ce stade, même une petite modification peut avoir des conséquences imprévisibles. Ajouter une ligne peut fausser un total. Copier une cellule peut casser un calcul ailleurs. Filtrer un tableau peut donner une mauvaise lecture des résultats.
Ce n’est pas un problème de niveau. C’est un problème de conception. Beaucoup d’utilisateurs connaissent les formules, parfois même très bien. Mais ils n’ont jamais appris à structurer un fichier Excel comme un véritable outil de travail. Or Excel n’est pas fait pour être bricolé indéfiniment. Il est fait pour être pensé.
Et tant qu’on ne change pas cette approche, les mêmes erreurs reviennent encore et encore, quels que soient les calculs utilisés.
Aller plus loin que les formules : apprendre Excel comme un outil professionnel
Les erreurs que nous avons vues dans cet article ne sont pas des cas isolés. Elles font partie du quotidien de milliers d’utilisateurs Excel. Et le plus problématique, c’est qu’elles passent souvent inaperçues.
Cellules vides, filtres actifs, copier/coller approximatif, références déplacées… chaque détail pris séparément semble anodin. Mais mis bout à bout, ils transforment progressivement un fichier en un outil fragile, difficile à maintenir et peu fiable.
C’est pour cette raison qu’apprendre Excel uniquement à travers des fonctions ou des astuces ponctuelles ne suffit pas. Ce qui fait réellement la différence, ce n’est pas de connaître quelques formules de plus, mais de comprendre comment structurer un fichier, organiser ses données, sécuriser ses calculs et construire une logique claire dès le départ.
C’est exactement ce que nous abordons en formation : une approche professionnelle d’Excel, orientée fiabilité, lisibilité et efficacité, bien au-delà des simples recettes trouvées en ligne.
Si vous souhaitez aller plus loin et apprendre à utiliser Excel comme un véritable outil de travail, que ce soit pour gagner du temps, éviter les erreurs ou fiabiliser vos fichiers, nos formations vous accompagnent pas à pas, du niveau débutant jusqu’aux usages avancés.